21 Compression
21 压缩
Hi, I'm Carrie Anne, and welcome to Crash Course Computer Science!
嗨,我是 Carrie Anne,欢迎收看计算机科学速成课!
Last episode we talked about Files, bundles of data, stored on a computer, that
上集我们讨论了文件格式,
are formatted and arranged to encode information, like text, sound or images.
如何编码文字,声音,图片
We even discussed some basic file formats, like text, wave, and bitmap.
还举了具体例子 .txt .wav .bmp
While these formats are perfectly fine and still used today,
这些格式虽然管用,而且现在还在用,
their simplicity also means they're not very efficient.
但它们的简单性意味着效率不高
Ideally, we want files to be as small as possible, so we can store lots of them without filling
我们希望文件能小一点,
up our hard drives, and also transmit them more quickly.
这样能存大量文件,传输也会快一些
Nothing is more frustrating than waiting for an email attachment to download. Ugh!
等邮件附件下载烦死人了
The answer is compression, which literally squeezes data into a smaller size.
解决方法是 压缩,把数据占用的空间压得更小
To do this, we have to encode data using fewer bits than the original representation.
用更少的位(bit)来表示数据
That might sound like magic, but it's actually computer science!
听起来像魔法,但其实是计算机科学!
Lets return to our old friend from last episode, Mr. Pac-man!
我们继续用上集的 吃豆人例子,
This image is 4 pixels by 4 pixels.
图像是 4像素x4像素
As we discussed, image data is typically stored as a list of pixel values.
之前说过,图像一般存成一长串像素值
To know where rows end, image files have metadata, which defines properties like dimensions.
为了知道一行在哪里结束,图像要有元数据,写明尺寸等属性
But, to keep it simple today, we're not going to worry about it.
但为了简单起见,今天忽略这些细节
If you mix full intensity red, green and blue that's 255 for all
如果红绿蓝都是 255
three values you get the color white.
会得到白色
If you mix full intensity red and green, but no blue (it's 0), you get yellow.
如果混合 255红色和255绿色,会得到黄色
We have 16 pixels in our image, and each of those needs 3 bytes of color data.
这个图像有16个像素(4x4), 每个像素3个字节
That means this image's data will consume 48 bytes of storage.
总共占48个字节(16x3=48)
But, we can compress the data and pack it into a smaller number of bytes than 48!
但我们可以压缩到少于 48 个字节
One way to compress data is to reduce repeated or redundant information.
一种方法是 减少重复信息
The most straightforward way to do this is called Run-Length Encoding.
最简单的方法叫 游程编码(Run-Length Encoding)
This takes advantage of the fact that there are often runs of identical values in files.
适合经常出现相同值的文件
For example, in our pac-man image, there are 7 yellow pixels in a row.
比如吃豆人 有7个连续黄色像素
Instead of encoding redundant data: yellow pixel, yellow pixel, yellow pixel, and so
与其全存下来:黄色,黄色,黄色...
on, we can just say "there's 7 yellow pixels in a row" by inserting
可以插入一个额外字节,
an extra byte that specifies the length of the run, like so:
代表有7个连续黄色像素
And then we can eliminate the redundant data behind it.
然后删掉后面的重复数据.
To ensure that computers don't get confused with which bytes are run lengths and which
为了让计算机能分辨哪些字节是"长度"
bytes represent color, we have to be consistent in how we apply this scheme.
哪些字节是"颜色",格式要一致
So, we need to preface all pixels with their run-length.
所以我们要给所有像素前面标上长度

In some cases, this actually adds data, but on the whole, we've dramatically reduced
有时候数据反而会变多,但就这个例子而言
the number of bytes we need to encode this image.
我们大大减少了字节数,
We're now at 24 bytes, down from 48.
之前是48 现在是24
That's 50% smaller!
小了50%!
A huge saving!
省了很多空间!
Also note that we haven't lost any data.
还有,我们没有损失任何数据,
We can easily expand this back to the original form without any degradation.
我们可以轻易恢复到原来的数据
A compression technique that has this characteristic is called
这叫"无损压缩",
lossless compression, because we don't lose anything.
没有丢失任何数据
The decompressed data is identical to the original before compression, bit for bit.
解压缩后,数据和压缩前完全一样
Let's take a look at another type of lossless compression, where
我们来看另一种无损压缩,
blocks of data are replaced by more compact representations.
它用更紧凑的方式表示数据块
This is sort of like " don't forget to be awesome " being replaced by DFTBA.
有点像 "别忘了变厉害" 简写成 DFTBA
To do this, we need a dictionary that stores the mapping from codes to data.
为此,我们需要一个字典,存储"代码"和"数据"间的对应关系
Lets see how this works for our example.
我们看个例子
We can view our image as not just a string of individual pixels,
我们可以把图像看成一块块,
but as little blocks of data.
而不是一个个像素
For simplicity, we're going to use pixel pairs, which are 6 bytes long,
为了简单,我们把2个像素当成1块(占6个字节)
but blocks can be any size.
但你也可以定成其他大小
In our example, there are only four pairings: White-yellow, black-yellow,
我们只有四对: 白黄 黑黄
yellow-yellow and white-white.
黄黄 白白
Those are the data blocks in our dictionary we want to generate compact codes for.
我们会为这四对 生成紧凑代码(compact codes)
What's interesting, is that these blocks occur at different frequencies.
有趣的是,这些块的出现频率不同
One method for generating efficient codes is building a Huffman Tree, invented by David
1950年代 大卫·霍夫曼 发明了一种高效编码方式叫,"霍夫曼树"(Huffman Tree)
Huffman while he was a student at MIT in the 1950s.
当时他是麻省理工学院的学生
His algorithm goes like this.
算法是这样的
First, you layout all the possible blocks and their frequencies.
首先,列出所有块和出现频率,
At every round, you select the two with the lowest frequencies.
每轮选两个最低的频率
Here, that's Black-Yellow and White-White, each with a frequency of 1.
这里 黑黄 和 白白 的频率最低,它们都是 1
You combine these into a little tree. which have a combined frequency of 2,
可以把它们组成一个树,
so we record that.
总频率 2
And now one step of the algorithm done.
现在完成了一轮算法
Now we repeat the process.
现在我们重复这样做
This time we have three things to choose from.
这次有3个可选
Just like before, we select the two with the lowest frequency, put them into a little tree,
就像上次一样,选频率最低的两个,
and record the new total frequency of all the sub items.
放在一起,并记录总频率
Ok, we're almost done.
好,我们快完成了
This time it's easy to select the two items with the lowest frequency
这次很简单,
because there are only two things left to pick.
因为只有2个选择
We combine these into a tree, and now we're done!
把它们组合成一棵树就完成了!
Our tree looks like this, and it has a very cool property: it's arranged by frequency,
现在看起来像这样,它有一个很酷的属性:按频率排列
with less common items lower down.
频率低的在下面
So, now we have a tree, but you may be wondering how this gets us to a dictionary.
现在有了一棵树,你可能在想 "怎么把树变成字典?"
Well, we use our frequency-sorted tree to generate the codes we need
我们可以把每个分支用 0 和 1 标注,
by labeling each branch with a 0 or a 1, like so.
就像这样
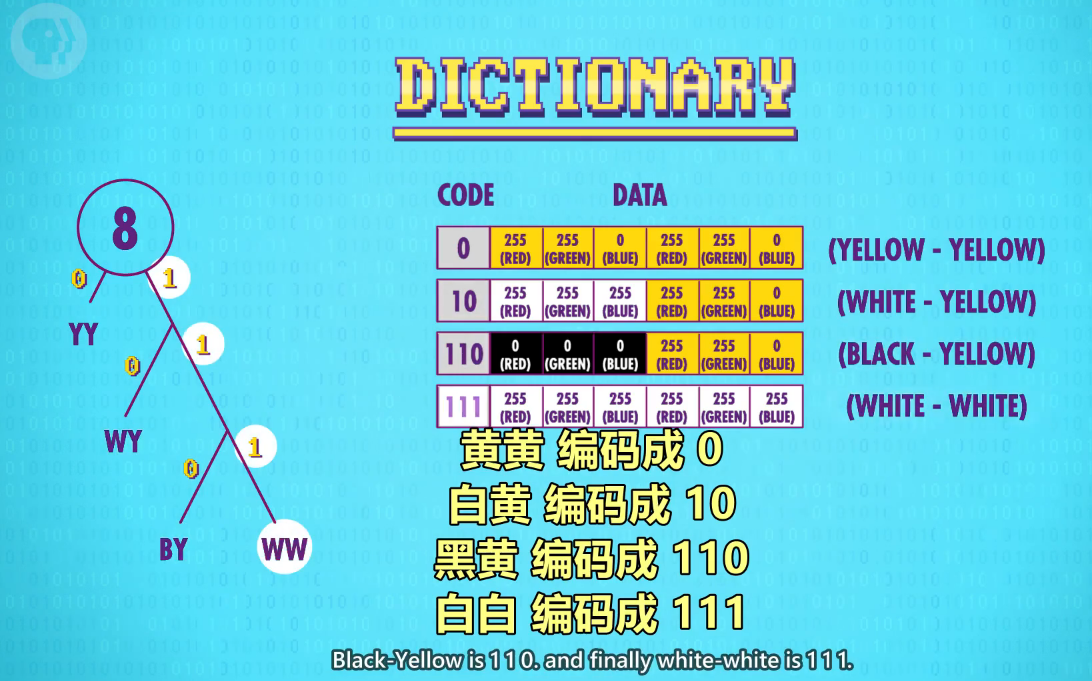
With this, we can write out our code dictionary.
现在可以生成字典
Yellow-yellow is encoded as just a single 0. White-yellow is encoded as 10
黄黄 编码成 0 ,白黄 编码成 10,
Black-Yellow is 1 1 0. and finally white-white is 1 1 1.
黑黄 编码成 110,白白 编码成 111
The really cool thing about these codewords is that there's no way to
酷的地方是 它们绝对不会冲突
have conflicting codes, because each path down the tree is unique.
因为树的每条路径是唯一的
This means our codes are prefix-free, that is no code starts with another complete code.
意味着代码是"无前缀"的,没有代码是以另一个代码开头的
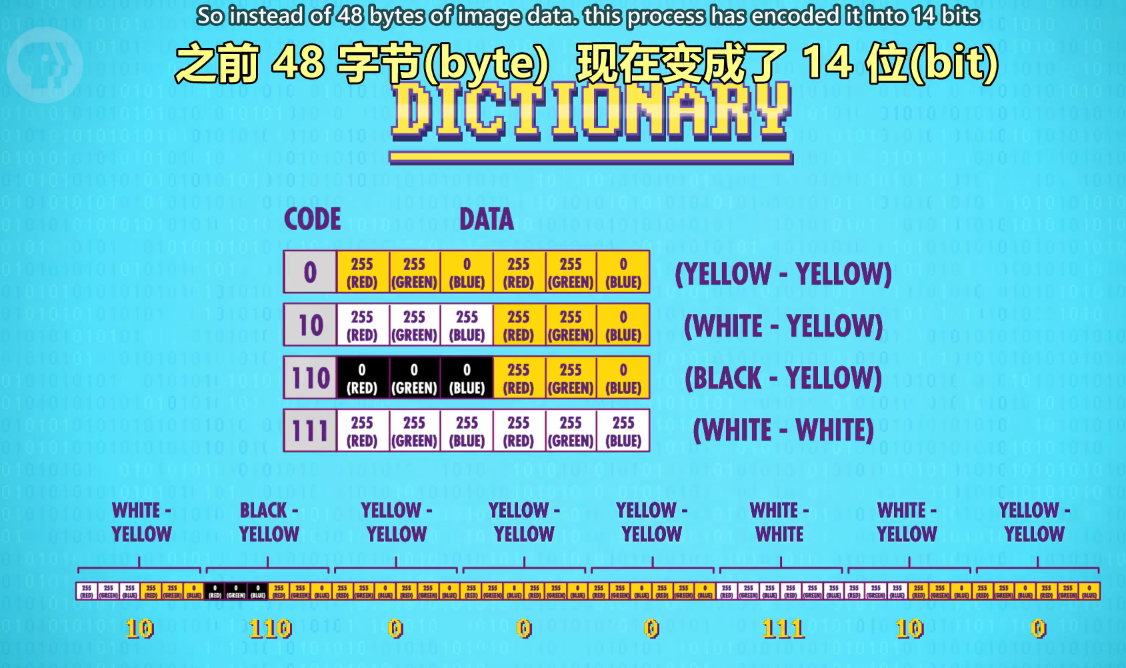
Now, let's return to our image data and compress it!
现在我们来压缩!
NOT BYTES -BITS!! That's less than 2 bytes of data!
注意是位(bit)! 不是字节(byte)!,14位(bit) 还不到2个字节(byte)!
But, don't break out the champagne quite yet!
但,先别急着开香槟!
This data is meaningless unless we also save our code dictionary.
字典也要保存下来,否则 14 bit 毫无意义
So, we'll need to append it to the front of the image data, like this.
所以我们把字典 加到 14 bit 前面,就像这样
Now, including the dictionary, our image data is 30 bytes long.
现在加上字典,图像是 30 个字节(bytes) ,
That's still a significant improvement over 48 bytes.
比 48 字节好很多

The two approaches we discussed,
消除冗余和"用更紧凑的表示方法",这两种方法通常会组合使用
removing redundancies and using more compact representations, are often combined,
消除冗余和"用更紧凑的表示方法",这两种方法通常会组合使用
and underlie almost all lossless compressed file formats,
几乎所有无损压缩格式都用了它们,
like GIF, PNG, PDF and ZIP files.
比如 GIF, PNG, PDF, ZIP
Both run-length encoding and dictionary coders are lossless compression techniques.
游程编码 和 字典编码 都是无损压缩
No information is lost; when you decompress, you get the original file.
压缩时不会丢失信息,解压后,数据和之前完全一样
That's really important for many types of files.
无损对很多文件很重要
Like, it'd be very odd if I zipped up a word document to send to you,
比如我给你发了个压缩的 word 文档,
and when you decompressed it on your computer, the text was different.
你解压之后发现内容变了,这就很糟糕了
But, there are other types of files where we can get away with little changes, perhaps
但其他一些文件,丢掉一些数据没什么关系
by removing unnecessary or less important information, especially information
丢掉那些人类
that human perception is not good at detecting.
看不出区别的数据
And this trick underlies most lossy compression techniques.
大多数有损压缩技术,都用到了这点
These tend to be pretty complicated, so we're going to attack this at a conceptual level.
实际细节比较复杂,所以我们讲概念就好
Let's take sound as an example.
以声音为例,
Your hearing is not perfect.
你的听力不是完美的
We can hear some frequencies of sound better than others.
有些频率我们很擅长,
And there are some we can't hear at all, like ultrasound.
其他一些我们根本听不见,比如超声波
Unless you're a bat.
除非你是蝙蝠
Basically, if we make a recording of music, and there's data in the ultrasonic frequency range,
举个例子,如果录音乐,
we can discard it, because we know that humans can't hear it.
超声波数据都可以扔掉,因为人类听不到超声波
On the other hand, humans are very sensitive to frequencies in the vocal range, like people
另一方面,人类对人声很敏感,
singing, so it's best to preserve quality there as much as possible.
所以应该尽可能保持原样
Deep bass is somewhere in between.
低音介于两者之间,
Humans can hear it, but we're less attuned to it.
人类听得到,但不怎么敏感
We mostly sense it.
一般是感觉到震动
Lossy audio compressors takes advantage of this, and encode different
有损音频压缩利用这一点,
frequency bands at different precisions.
用不同精度编码不同频段
Even if the result is rougher, it's likely that users won't perceive the difference.
听不出什么区别,
Or at least it doesn't dramatically affect the experience.
不会明显影响体验
And here comes the hate mail from the audiophiles!
音乐发烧友估计要吐槽了!
You encounter this type of audio compression all the time.
日常生活中你会经常碰到这类音频压缩
It's one of the reasons you sound different on a cellphone versus in person.
所以你在电话里的声音 和现实中不一样
The audio data is being compressed, allowing more people to take calls at once.
压缩音频是为了让更多人能同时打电话
As the signal quality or bandwidth get worse, compression algorithms remove more data,
如果网速变慢了,压缩算法会删更多数据
further reducing precision, which is why Skype calls sometimes sound like robots talking.
进一步降低声音质量,所以 Skype 通话有时听起来像机器人
Compared to an uncompressed audio format, like a WAV or FLAC (there we go, got the audiophiles back)
和没压缩的音频格式相比,比如 WAV 或 FLAC,( 这下音乐发烧友满意了)
compressed audio files, like MP3s, are often 10 times smaller.
压缩音频文件如 MP3,能小10倍甚至更多.
That's a huge saving!
省了超多空间!
And it's why I've got a killer music collection on my retro iPod.
所以我的旧 iPod 上有一堆超棒的歌
Don't judge.
别批判我
This idea of discarding or reducing precision in a manner that aligns with human perception
这种删掉人类无法感知的数据的方法,
is called perceptual coding,
叫"感知编码"
and it relies on models of human perception,
它依赖于人类的感知模型,
which come from a field of study called Psychophysics.
模型来自"心理物理学"领域
This same idea is the basis of lossy compressed image formats, most famously JPEGs.
这是各种"有损压缩图像格式"的基础,最著名的是 JPEG
Like hearing, the human visual system is imperfect.
就像听力一样,人的视觉系统也不是完美的.
We're really good at detecting sharp contrasts, like the edges of objects,
我们善于看到尖锐对比,比如物体的边缘
but our perceptual system isn't so hot with subtle color variations.
但我们看不出颜色的细微变化
JPEG takes advantage of this by breaking images up into blocks of 8x8 pixels,
JPEG 利用了这一点,把图像分解成 8x8 像素块
then throwing away a lot of the high-frequency spatial data.
然后删掉大量高频率空间数据
For example, take this photo of our directors dog Noodle.
举个例子,这是导演的狗,面面
So cute!
超可爱!
Let's look at a patch of 8x8 pixels.
我们来看其中一个 8x8 像素
Pretty much every pixel is different from its neighbor,
几乎每个像素都和相邻像素不同,
making it hard to compress with loss-less techniques because there's just a lot going on.
用无损技术很难压缩,因为太多不同点了
Lots of little details.
很多小细节
But human perception doesn't register all those details.
但人眼看不出这些细节
So, we can discard a lot of that detail, and replace it with a simplified patch like this.
因此可以删掉很多,用这样一个简单的块来代替
This maintains the visual essence, but might only use 10% of the data.
这看起来一样,但可能只占10%的原始数据
We can do this for all the patches in the image and get this result.
我们可以对所有 8x8 块做一样的操作
You can still see it's a dog, but the image is rougher.
图片依然可以认出是一只狗,只是更粗糙一些
So, that's an extreme example, going from a slightly compressed JPEG to a highly compressed one,
以上例子比较极端,进行了高度压缩,
one-eighth the original file size.
只有原始大小的八分之一
Often, you can get away with a quality somewhere in between, and perceptually,
通常你可以取得平衡,图片看起来差不多,
it's basically the same as the original.
但文件小不少
Can you tell the difference between the two?
你看得出两张图的区别吗?
Probably not, but I should mention that video compression plays a role in that too,
估计看不出,但我想提一下,视频压缩也造成了影响
since I'm literally being compressed in a video right now.
毕竟你现在在看视频啊
Videos are really just long sequences of images, so a lot of what I said
视频只是一长串连续图片,
about them applies here too.
所以图片的很多方面也适用于视频
But videos can do some extra clever stuff, because between frames,
但视频可以做一些小技巧,因为帧和帧之间很多像素一样
a lot of pixels are going to be the same.
但视频可以做一些小技巧,因为帧和帧之间很多像素一样
Like this whole background behind me!
比如我后面的背景!
This is called temporal redundancy.
这叫 时间冗余
We don't need to re-transmit those pixels every frame of the video.
视频里不用每一帧都存这些像素,
We can just copy patches of data forward.
可以只存变了的部分
When there are small pixel differences, like the readout on this frequency generator behind me,
当帧和帧之间有小小的差异时,比如后面这个频率发生器
most video formats send data that encodes just the difference between patches,
很多视频编码格式,只存变化的部分
which is more efficient than re-transmitting all the pixels afresh, again taking advantage
这比存所有像素更有效率,
of inter-frame similarity.
利用了帧和帧之间的相似性
The fanciest video compression formats go one step further.
更高级的视频压缩格式 会更进一步
They find patches that are similar between frames, and not only copy them forward, with
找出帧和帧之间相似的补丁,
or without differences, but also can apply simple effects to them, like a shift or rotation.
然后用简单效果实现,比如移动和旋转
They can also lighten or darken a patch between frames.
变亮和变暗
So, if I move my hand side to side like this the video compressor will identify the similarity,
如果我这样摆手,视频压缩器会识别到相似性
capture my hand in one or more patches, then just move these patches around between frames.
用一个或多个补丁代表我的手,然后帧之间直接移动这些补丁
You're actually seeing my hand from the past kinda freaky, but it uses a lot less data.
所以你看到的是我过去的手(不是实时的),有点可怕 但数据量少得多
MPEG-4 videos, a common standard, are often 20 to 200 times
MPEG-4 是常见标准,
smaller than the original, uncompressed file.
可以比原文件小20倍到200倍
However, encoding frames as translations and rotations of patches from previous frames
但用补丁的移动和旋转 来更新画面
can go horribly wrong when you compress too heavily, and there isn't
当压缩太严重时会出错,
enough space to update pixel data inside of the patches.
没有足够空间更新补丁内的像素
The video player will forge ahead, applying the right motions,
即使补丁是错的,
even if the patch data is wrong.
视频播放器也会照样播放
And this leads to some hilarious and trippy effects, which I'm sure you've seen.
导致一些怪异又搞笑的结果,你肯定见过这些.
Overall, it's extremely useful to have compression techniques for all the types of data I discussed today.
总的来说,压缩对大部分文件类型都有用
(I guess our imperfect vision and hearing are "useful," too.)
从这个角度来讲,人类不完美的视觉和听觉 也算有用
And it's important to know about compression because it allows users to
学习压缩非常重要,因为可以高效
store pictures, music, and videos in efficient ways.
存储图片,音乐,视频
Without it, streaming your favorite Carpool Karaoke videos on YouTube would be nearly impossible,
如果没有压缩,在 YouTube 看"明星拼车唱歌"几乎不可能
due to bandwidth and the economics of transmitting that volume of data for free.
因为你的带宽可能不够(会很卡),而且供应商不愿意免费传输那么多数据
And now when your Skype calls sound like they're being taken over by demons,
现在你知道为什么打 Skype 电话,
you'll know what's really going on.
有时像在和恶魔通话
I'll see you next week.
下周见