34 Machine Learning & Artificial Intelligence
34 机器学习&人工智能
Hi, I'm Carrie Anne, and welcome to Crash Course Computer Science!
嗨,我是 Carrie Anne,欢迎收看计算机科学速成课!
As we've touched on many times in this series,
我们之前说过,
computers are incredible at storing, organizing,
计算机很擅长存放,整理,
fetching and processing huge volumes of data.
获取和处理大量数据
That's perfect for things like e-commerce websites with millions of items for sale,
很适合有上百万商品的电商网站
and for storing billions of health records for quick access by doctors.
或是存几十亿条健康记录,方便医生看.
But what if we want to use computers not just to fetch and display data,
但是如果我们想用计算机不仅仅是为了获取和显示数据,
but to actually make decisions about data?
但如果想根据数据做决定呢?
This is the essence of machine learning
这是机器学习的本质
algorithms that give computers the ability to learn from data,
机器学习算法让计算机可以从数据中学习,
and then make predictions and decisions.
然后自行做出预测和决定
Computer prosgrams with this ability
能自我学习的程序很有用,
are extremely useful in answering questions like Is an email spam?
比如判断是不是垃圾邮件
Does a person's heart have arrhythmia?
这人有心律失常吗?
or what video should youtube recommend after this one?
YouTube 的下一个视频该推荐哪个?
While useful, we probably wouldn't describe these programs as "intelligent"
虽然有用,但我们不会说它
in the same way we think of human intelligence.
有人类一般的智能
So, even though the terms are often interchanged,
虽然 AI 和 ML 这两词经常混着用
most computer scientists would say that machine learning is a set of techniques
大多数计算机科学家会说 ,
that sits inside the even more ambitious goal of Artificial Intelligence,
机器学习是为了实现人工智能这个更宏大目标的技术之一
or AI for short.
人工智能简称 AI
Machine Learning and AI algorithms tend to be pretty sophisticated.
机器学习和人工智能算法一般都很复杂
So rather than wading into the mechanics of how they work,
所以我们不讲具体细节
we're going to focus on what the algorithms do conceptually.
重点讲概念
Let's start with a simple example:
我们从简单例子开始:
deciding if a moth is a Luna Moth or an Emperor Moth.
判断飞蛾是"月蛾"还是"帝蛾"
This decision process is called classification,
这叫"分类"
and an algorithm that does it is called a classifier.
做分类的算法叫 "分类器"
Although there are techniques that can use raw data for training
虽然我们可以用 照片和声音
like photos and sounds -
来训练算法
many algorithms reduce the complexity of real world objects
很多算法会减少复杂性
and phenomena into what are called features.
把数据简化成 "特征"
Features are values that usefully characterize the things we wish to classify.
特征是用来帮助"分类"的值
For our moth example, we're going to use two features: "wingspan" and "mass".
对于之前的飞蛾分类例子,我们用两个特征:"翼展"和"重量"
In order to train our machine learning classifier to make good predictions,
为了训练"分类器"做出好的预测,
we're going to need training data.
我们需要"训练数据"
To get that,
为了得到数据
we'd send an entomologist out into a forest to collect data for both luna and emperor moths.
我们派昆虫学家到森林里 收集"月蛾"和"帝蛾"的数据
These experts can recognize different moths,
专家可以认出不同飞蛾,
so they not only record the feature values,
所以专家不只记录特征值,
but also label that data with the actual moth species.
还会把种类也写上
This is called labeled data.
这叫 "标记数据"
Because we only have two features,
因为只有两个特征
it's easy to visualize this data in a scatterplot.
很容易用散点图把数据视觉化
Here, I've plotted data for 100 Emperor Moths in red and 100 Luna Moths in blue.
红色标了100个帝蛾,蓝色标了100个月蛾
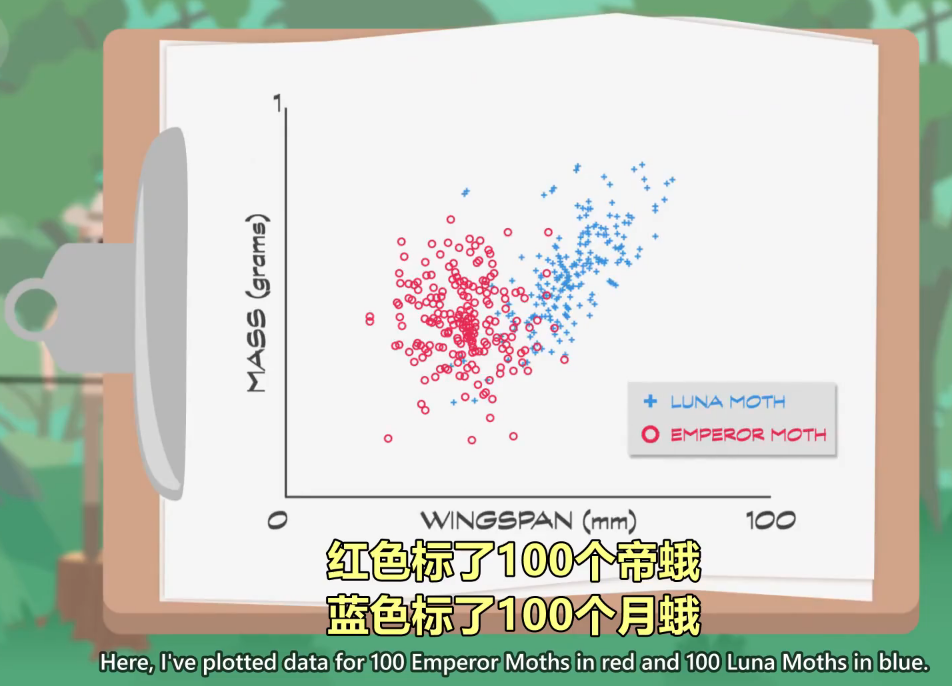
We can see that the species make two groupings, but.
可以看到大致分成了两组
there's some overlap in the middle
但中间有一定重叠
so it's not entirely obvious how to best separate the two.
所以想完全区分两个组比较困难
That's what machine learning algorithms do
所以机器学习算法登场
find optimal separations!
找出最佳区分
I'm just going to eyeball it
我用肉眼大致估算下
and say anything less than 45 millimeters in wingspan is likely to be an Emperor Moth.
然后判断 翼展小于45毫米的 很可能是帝蛾
We can add another division that says additionally mass must be less than .75
可以再加一个条件,重量必须小于.75
in order for our guess to be Emperor Moth.
才算是帝蛾。
These lines that chop up the decision space are called decision boundaries.
这些线叫 "决策边界"
If we look closely at our data,
如果仔细看数据
we can see that 86 emperor moths would correctly end up inside the emperor decision region,
86只帝蛾在正确的区域
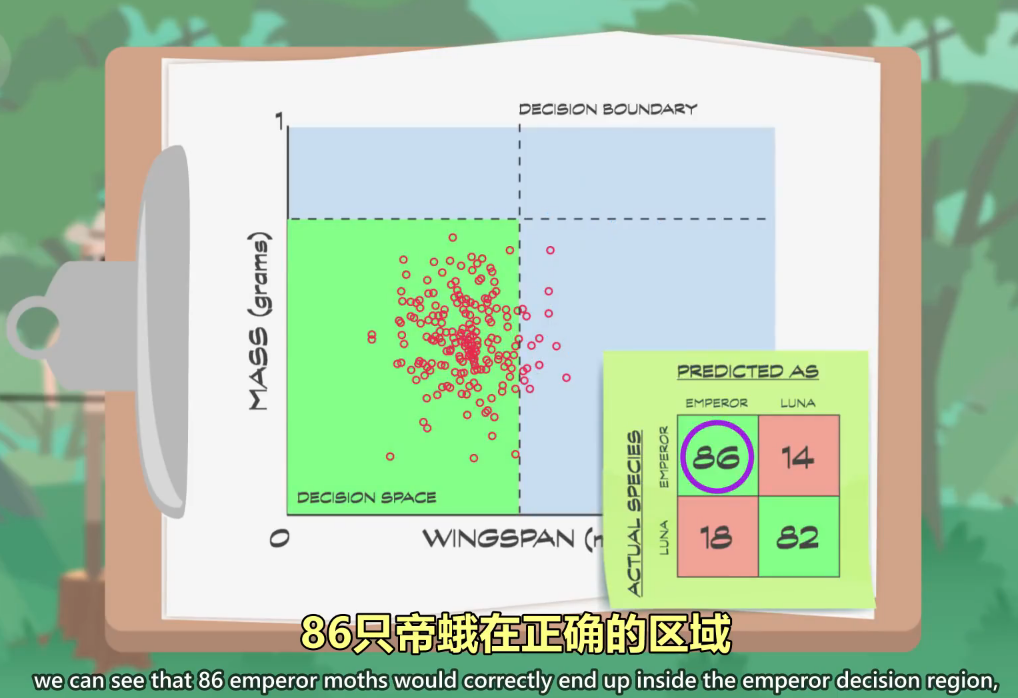
but 14 would end up incorrectly in luna moth territory.
但剩下14只在错误的区域
On the other hand, 82 luna moths would be correct,
另一方面,82只月蛾在正确的区域
with 18 falling onto the wrong side.
18个在错误的区域
A table, like this, showing where a classifier gets things right and wrong
这里有个表 记录正确数和错误数
is called a confusion matrix...
这表叫"混淆矩阵"
which probably should have also been the title of the last two movies in the Matrix Trilogy!
黑客帝国三部曲的后两部也许该用这个标题
Notice that there's no way for us to draw lines that give us 100% accuracy.
注意我们没法画出 100% 正确分类的线
If we lower our wingspan decision boundary,
降低翼展的决策边界,
we misclassify more Emperor moths as Lunas.
会把更多"帝蛾"误分类成"月蛾"
If we raise it, we misclassify more Luna moths.
如果提高,会把更多月蛾分错类.
The job of machine learning algorithms,
机器学习算法的目的
at a high level,
在一个高的水平
is to maximize correct classifications while minimizing errors
是最大化正确分类 + 最小化错误分类
On our training data, we get 168 moths correct, and 32 moths wrong,
在训练数据中,有168个正确,32个错误
for an average classification accuracy of 84%.
平均准确率84%
Now, using these decision boundaries,
用这些决策边界
if we go out into the forest and encounter an unknown moth,
如果我们进入森林,碰到一只不认识的飞蛾,
we can measure its features and plot it onto our decision space.
我们可以测量它的特征, 并绘制到决策空间上
This is unlabeled data.
这叫 "未标签数据"
Our decision boundaries offer a guess as to what species the moth is.
决策边界可以猜测飞蛾种类
In this case, we'd predict it's a Luna Moth.
这里我们预测是"月蛾"
This simple approach, of dividing the decision space up into boxes,
这个把决策空间 切成几个盒子的简单方法
can be represented by what's called a decision tree,
可以用"决策树"来表示
which would look like this pictorially or could be written in code using If-Statements, like this.
画成图像,会像左侧,用 if 语句写代码,会像右侧
A machine learning algorithm that produces decision trees
生成决策树的 机器学习算法
needs to choose what features to divide on
需要选择用什么特征来分类
and then for each of those features, what values to use for the division.
每个特征用什么值
Decision Trees are just one basic example of a machine learning technique.
决策树只是机器学习的一个简单例子
There are hundreds of algorithms in computer science literature today.
如今有数百种算法,
And more are being published all the time.
而且新算法不断出现
A few algorithms even use many decision trees working together to make a prediction.
一些算法甚至用多个"决策树"来预测
Computer scientists smugly call those Forests
计算机科学家叫这个"森林",
because they contain lots of trees.
因为有多颗树嘛
There are also non-tree-based approaches,
也有不用树的方法,
like Support Vector Machines,
比如"支持向量机"
which essentially slice up the decision space using arbitrary lines.
本质上是用任意线段来切分"决策空间"
And these don't have to be straight lines;
不一定是直线
they can be polynomials or some other fancy mathematical function.
可以是多项式或其他数学函数
Like before, it's the machine learning algorithm's job
就像之前,机器学习算法负责
to figure out the best lines to provide the most accurate decision boundaries.
找出最好的线,最准的决策边界
So far, my examples have only had two features,
之前的例子只有两个特征,
which is easy enough for a human to figure out.
人类也可以轻松做到
If we add a third feature,
如果加第3个特征,
let's say, length of antennae,
比如"触角长度"
then our 2D lines become 3D planes,
那么2D线段,会变成3D平面
creating decision boundaries in three dimensions.
在三个维度上做决策边界
These planes don't have to be straight either.
这些平面不必是直的
Plus, a truly useful classifier would contend with many different moth species.
而且 真正有用的分类器 会有很多飞蛾种类

Now I think you'd agree this is getting too complicated to figure out by hand
你可能会同意 现在变得太复杂了
But even this is a very basic example
但这也只是个简单例子
just three features and five moth species.
只有3个特征和5个品种
We can still show it in this 3D scatter plot.
我们依然可以用 3D散点图 画出来
Unfortunately, there's no good way to visualize four features at once, or twenty features,
不幸的是,一次性看4个或20个特征,没有好的方法
let alone hundreds or even thousands of features.
更别说成百上千的特征了
But that's what many real-world machine learning problems face.
但这正是机器学习要面临的问题
Can YOU imagine trying to figure out the equation for a hyperplane
你能想象靠手工 在一个上千维度的决策空间里
rippling through a thousand-dimensional decision space?
给超平面(Hyperplane)找出一个方程吗
Probably not,
大概不行
but computers, with clever machine learning algorithms can
但聪明的机器学习算法可以做到
and they do, all day long, on computers at places like Google, Facebook, Microsoft and Amazon.
Google,Facebook,微软和亚马逊的计算机里,整天都在跑这些算法
Techniques like Decision Trees and Support Vector Machines are strongly rooted in the field of statistics,
决策树和"支持向量机"这样的技术,发源自统计学
which has dealt with making confident decisions,
统计学早在计算机出现前,
using data, long before computers ever existed.
就在用数据做决定
There's a very large class of widely used statistical machine learning techniques,
有一大类机器学习算法用了统计学
but there are also some approaches with no origins in statistics.
但也有不用统计学的算法
Most notable are artificial neural networks,
其中最值得注意的是 人工神经网络
which were inspired by neurons in our brains!
灵感来自大脑里的神经元
For a primer of biological neurons,
想学习神经元知识的人,
check out our three-part overview here,
可以看这3集
but basically neurons are cells
神经元是细胞
that process and transmit messages using electrical and chemical signals.
用电信号和化学信号 来处理和传输消息
They take one or more inputs from other cells,
它从其他细胞 得到一个或多个输入
process those signals,
然后处理信号
and then emit their own signal.
号并发出信号
These form into huge interconnected networks that are able to process complex information.
形成巨大的互联网络,能处理复杂的信息
Just like your brain watching this youtube video.
就像你的大脑 在看这个视频
Artificial Neurons are very similar.
人造神经元很类似
Each takes a series of inputs, combines them, and emits a signal.
可以接收多个输入,然后整合并发出一个信号
Rather than being electrical or chemical signals,
它不用电信号或化学信号
artificial neurons take numbers in, and spit numbers out.
而是吃数字进去,吐数字出来
They are organized into layers that are connected by links,
它们被放成一层层
forming a network of neurons, hence the name.
形成神经元网络,因此得名神经网络
Let's return to our moth example to see how neural nets can be used for classification.
回到飞蛾例子,看如何用神经网络分类
Our first layer the input layer -
我们的第一层 输入层 -
provides data from a single moth needing classification.
提供需要被分类的单个飞蛾数据
Again, we'll use mass and wingspan.
同样,这次也用重量和翼展
At the other end, we have an output layer, with two neurons:
另一边是输出层,有两个神经元:
one for Emperor Moth and another for Luna Moth.
一个是帝蛾,一个是月蛾
The most excited neuron will be our classification decision.
2个神经元里最兴奋的 就是分类结果
In between, we have a hidden layer,
中间有一个隐藏层
that transforms our inputs into outputs, and does the hard work of classification.
负责把输入变成输出,负责干分类这个重活
To see how this is done,
为了看看它是如何分类的
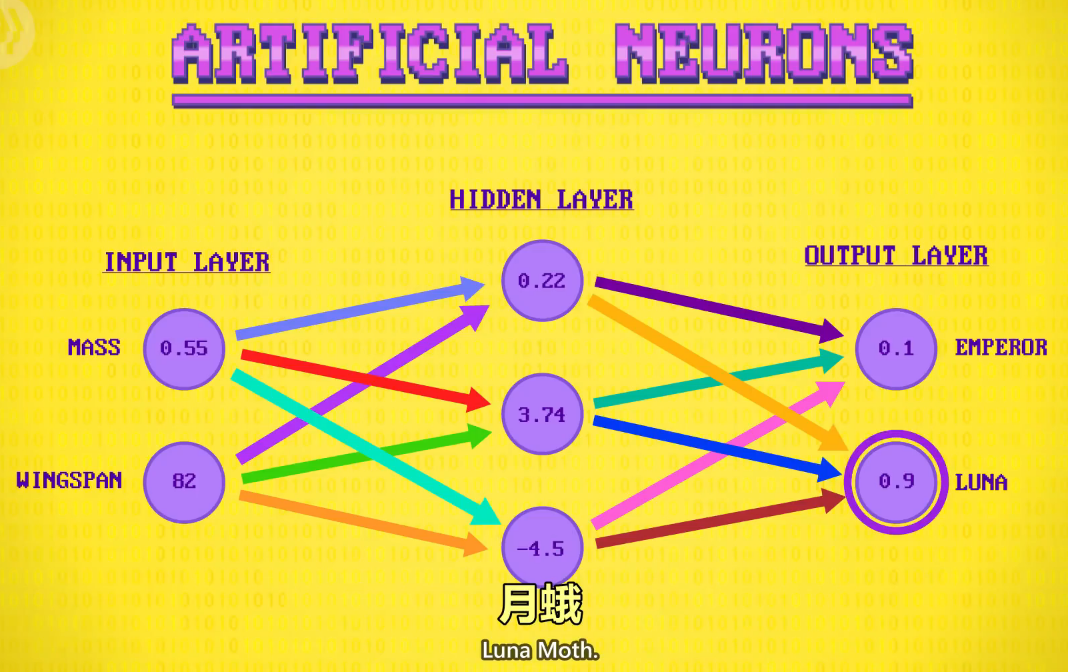
let's zoom into one neuron in the hidden layer.
我们放大"隐藏层"里的一个神经元
The first thing a neuron does is multiply each of its inputs by a specific weight,
神经元做的第一件事 ,是把每个输入乘以一个权重
let's say 2.8 for its first input, and .1 for it's second input.
假设2.8是第一个输入,0.1是第二个输入。
Then, it sums these weighted inputs together,
然后它会相加输入
which is in this case, is a grand total of 9.74.
总共是9.74
The neuron then applies a bias to this result
然后对这个结果,用一个偏差值处理
in other words, it adds or subtracts a fixed value,
意思是 加或减一个固定值
for example, minus six, for a new value of 3.74.
比如-6,得到3.74
These bias and inputs weights are initially set to random values when a neural network is created.
做神经网络时,这些偏差和权重,一开始会设置成随机值
Then, an algorithm goes in, and starts tweaking all those values to train the neural network,
然后算法会调整这些值 来训练神经网络
using labeled data for training and testing.
使用"标记数据"来训练和测试
This happens over many interactions, gradually improving accuracy
逐渐提高准确性
a process very much like human learning.
很像人类学习的过程
Finally, neurons have an activation function, also called a transfer function,
最后,神经元有激活函数,它也叫传递函数,
that gets applied to the output, performing a final mathematical modification to the result.
会应用于输出,对结果执行最后一次数学修改
For example, limiting the value to a range from negative one and positive one,
例如,把值限制在-1和+1之间
or setting any negative values to 0.
或把负数改成0
We'll use a linear transfer function that passes the value through unchanged,
我们用线性传递函数,它不会改变值
so 3.74 stays as 3.74.
所以3.74还是3.74
So for our example neuron,
所以这里的例子
given the inputs .55 and 82, the output would be 3.74.
输入0.55和82,输出3.74
This is just one neuron,
这只是一个神经元,
but this process of weighting, summing, biasing
但加权,求和,偏置,激活函数
and applying an activation function is computed for all neurons in a layer,
会应用于一层里的每个神经元
and the values propagate forward in the network, one layer at a time.
并向前传播,一次一层
In this example, the output neuron with the highest value is our decision:
数字最高的就是结果:
Luna Moth.
月蛾
Importantly, the hidden layer doesn't have to be just one layer
重要的是,隐藏层不是只能有一层,
it can be many layers deep.
可以有很多层
This is where the term deep learning comes from.
深度学习因此得名
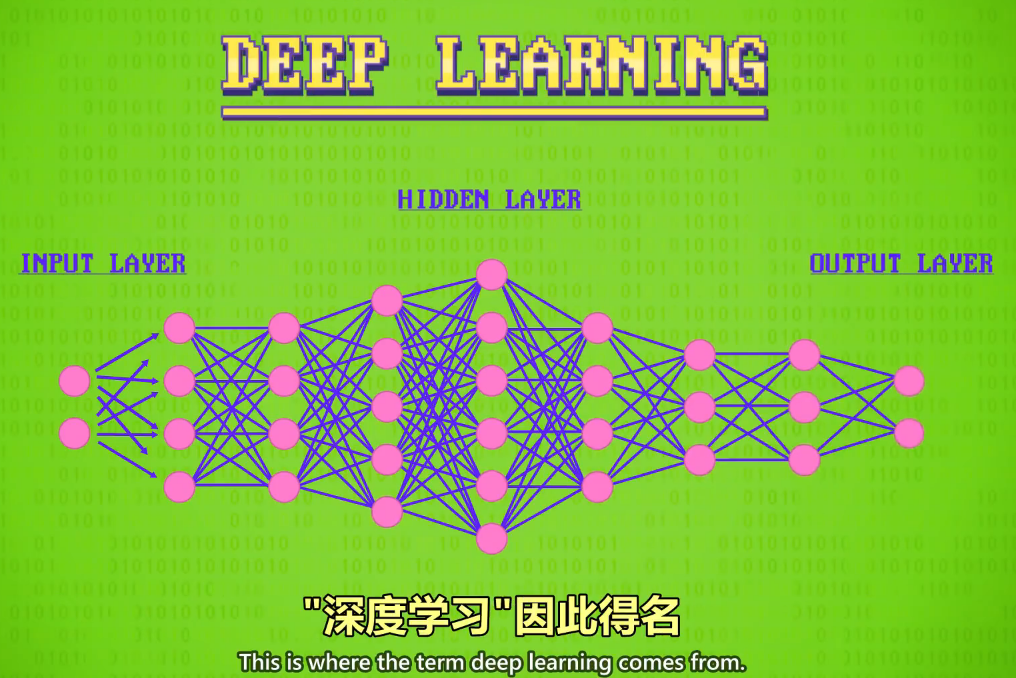
Training these more complicated networks takes a lot more computation and data.
训练更复杂的网络 需要更多的计算量和数据
Despite the fact that neural networks were invented over fifty years ago,
尽管神经网络50多年前就发明了
deep neural nets have only been practical very recently,
深层神经网络直到最近才成为可能
thanks to powerful processors,
感谢强大的处理器
but even more so, wicked fast GPUs.
和超快的GPU
So, thank you gamers for being so demanding about silky smooth framerates!
感谢游戏玩家对帧率的苛刻要求!
A couple of years ago, Google and Facebook
几年前,Google和Facebook
demonstrated deep neural nets that could find faces in photos as well as humans
展示了深度神经网络,在照片中识别人脸的准确率,和人一样高
and humans are really good at this!
人类可是很擅长这个的!
It was a huge milestone.
这是个巨大的里程碑
Now deep neural nets are driving cars,
现在有深层神经网络开车,
translating human speech,
翻译,
diagnosing medical conditions and much more.
诊断医疗状况等等
These algorithms are very sophisticated,
这些算法非常复杂,
but it's less clear if they should be described as "intelligent".
但还不够"聪明"
They can really only do one thing like classify moths, find faces, or translate languages.
它们只能做一件事,分类飞蛾,找人脸,翻译
This type of AI is called Weak AI or Narrow AI.
这种AI叫"弱AI"或"窄AI",
It's only intelligent at specific tasks.
只能做特定任务
But that doesn't mean it's not useful;
但这不意味着它没用
I mean medical devices that can make diagnoses,
能自动做出诊断的医疗设备,
and cars that can drive themselves are amazing!
和自动驾驶的汽车真是太棒了!
But do we need those computers to compose music
但我们是否需要这些计算机来创作音乐
and look up delicious recipes in their free time?
在空闲时间找美味食谱呢?
Probably not.
也许不要
Although that would be kinda cool.
如果有的话 还挺酷的
Truly general-purpose AI, one as smart and well-rounded as a human,
真正通用的,像人一样聪明的AI,
is called Strong AI.
叫 "强AI"
No one has demonstrated anything close to human-level artificial intelligence yet.
目前没人能做出来 接近人类智能的 AI
Some argue it's impossible,
有人认为不可能做出来
but many people point to the explosion of digitized knowledge
但许多人说 数字化知识的爆炸性增长
like Wikipedia articles, web pages, and Youtube videos -
比如维基百科,网页和Youtube视频 -
as the perfect kindling for Strong AI.
是"强 AI"的完美引燃物
Although you can only watch a maximum of 24 hours of youtube a day,
你一天最多只能看24小时的 YouTube,
a computer can watch millions of hours.
计算机可以看上百万小时
For example, IBM's Watson consults and synthesizes information from 200 million pages of content,
比如,IBM 的沃森吸收了 2 亿个网页的内容
including the full text of Wikipedia.
包括维基百科的全文
While not a Strong AI, Watson is pretty smart,
虽然不是"强AI" 但沃森也很聪明,
and it crushed its human competition in Jeopardy way back in 2011.
在2011年的知识竞答中碾压了人类
Not only can AIs gobble up huge volumes of information,
AI不仅可以吸收大量信息,也可以不断学习进步,
but they can also learn over time, often much faster than humans.
而且一般比人类快得多
In 2016, Google debuted AlphaGo,
2016 年 Google 推出 AlphaGo
a Narrow AI that plays the fiendishly complicated board game Go.
一个会玩围棋的窄AI
One of the ways it got so good and able to beat the very best human players,
它和自己的克隆版下无数次围棋,
was by playing clones of itself millions and millions of times.
从而打败最好的人类围棋选手
It learned what worked and what didn't,
学习什么管用,什么不管用,
and along the way, discovered successful strategies all by itself.
自己发现成功的策略
This is called Reinforcement Learning,
这叫 "强化学习"
and it's a super powerful approach.
是一种很强大的方法
In fact, it's very similar to how humans learn.
和人类的学习方式非常类似
People don't just magically acquire the ability to walk...
人类不是天生就会走路,
it takes thousands of hours of trial and error to figure it out.
是上千小时的试错学会的
Computers are now on the cusp of learning by trial and error,
计算机现在才刚学会反复试错来学习
and for many narrow problems,
对于很多狭窄的问题,
reinforcement learning is already widely used.
强化学习已被广??泛使用
What will be interesting to see, is if these types of learning techniques can be applied more broadly,
有趣的是,如果这类技术可以更广泛地应用
to create human-like, Strong AIs that learn much like how kids learn, but at super accelerated rates.
创造出类似人类的"强AI",能像人类小孩一样学习,但学习速度超快
If that happens, there are some pretty big changes in store for humanity
如果这发生了,对人类可能有相当大的影响
a topic we'll revisit later.
我们以后会讨论
Thanks for watching. See you next week.
感谢收看. 我们下周见