35 Computer Vision
35 计算机视觉
Hi, I'm Carrie Anne, and welcome to Crash Course Computer Science!
嗨 我是Carrie Anne,欢迎收看计算机科学速成课
Today, let's start by thinking about how important vision can be.
今天 我们来思考视觉的重要性
Most people rely on it to prepare food,
大部分人靠视觉来做饭
walk around obstacles,
越过障碍
read street signs,
读路牌
watch videos like this,
看视频
and do hundreds of other tasks.
以及无数其它任务
Vision is the highest bandwidth sense,
视觉是信息最多的感官,
and it provides a firehose of information about the state of the world and how to act on it.
比如周围的世界是怎样的,如何和世界交互
For this reason, computer scientists have been trying to give computers vision for half a century,
因此半个世纪来,计算机科学家一直在想办法让计算机有视觉
birthing the sub-field of computer vision.
因此诞生了"计算机视觉"这个领域
Its goal is to give computers the ability
目标是让计算机
to extract high-level understanding from digital images and videos.
理解图像和视频
As everyone with a digital camera or smartphone knows,
用过相机或手机的都知道,
computers are already really good at capturing photos with incredible fidelity and detail
可以拍出有惊人保真度和细节的照片
much better than humans in fact.
比人类强得多
But as computer vision professor Fei-Fei Li recently said,
但正如计算机视觉教授 李飞飞 最近说的
Just like to hear is the not the same as to listen.
听到"不等于"听懂"
To take pictures is not the same as to see."
看到不等于"看懂"
As a refresher, images on computers are most often stored as big grids of pixels.
复习一下,图像是像素网格
Each pixel is defined by a color, stored as a combination of three additive primary colors:
每个像素的颜色 通过三种基色定义:
red, green and blue.
红,绿,蓝
By combining different intensities of these three colors,
通过组合三种颜色的强度,
we can represent any color. what's called a RGB value,
可以得到任何颜色, 也叫 RGB 值
Perhaps the simplest computer vision algorithm
最简单的计算机视觉算法
and a good place to start -
最合适拿来入门的
is to track a colored object, like a bright pink ball.
是跟踪一个颜色物体,比如一个粉色的球
The first thing we need to do is record the ball's color.
首先,我们记下球的颜色,
For that, we'll take the RGB value of the centermost pixel.
保存最中心像素的 RGB 值
With that value saved, we can give a computer program an image,
然后给程序喂入图像,
and ask it to find the pixel with the closest color match.
让它找最接近这个颜色的像素
An algorithm like this might start in the upper right corner,
算法可以从左上角开始,
and check each pixel, one at time,
逐个检查像素
calculating the difference from our target color.
计算和目标颜色的差异
Now, having looked at every pixel,
检查了每个像素后,最贴近的像素,
the best match is very likely a pixel from our ball.
很可能就是球
We're not limited to running this algorithm on a single photo;
不只是这张图片,
we can do it for every frame in a video,
我们可以在视频的每一帧图片跑这个算法
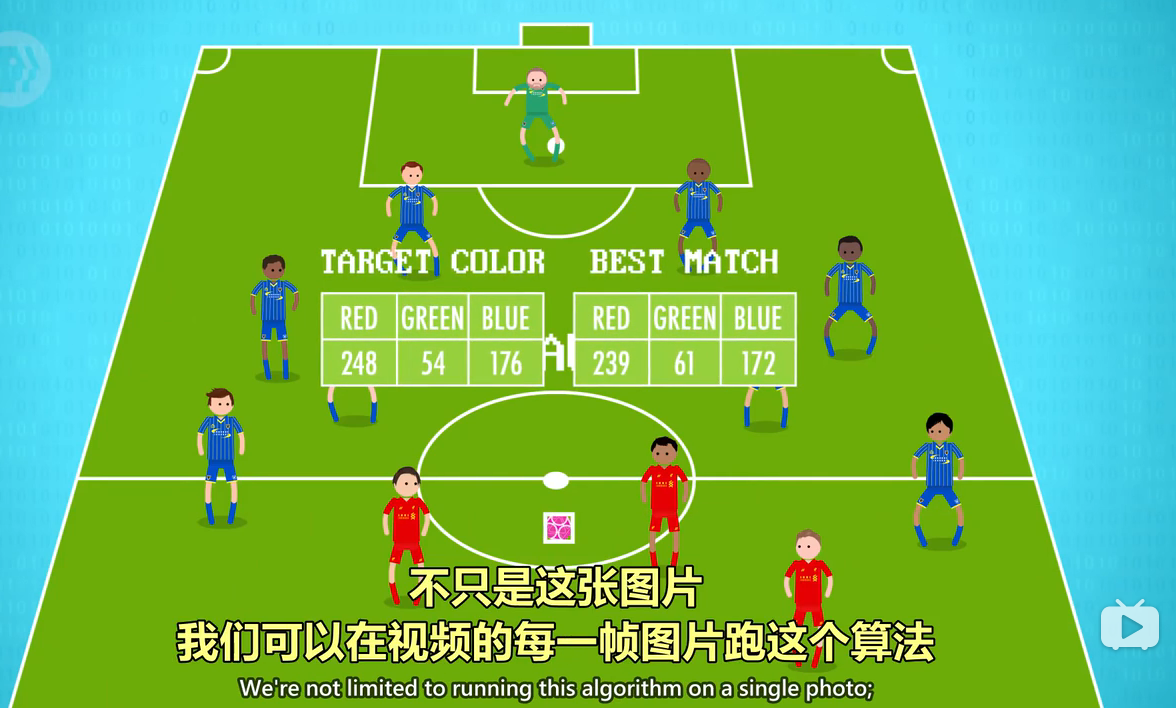
allowing us to track the ball over time.
跟踪球的位置
Of course, due to variations in lighting, shadows, and other effects,
当然,因为光线,阴影和其它影响
the ball on the field is almost certainly not going to be the exact same RGB value as our target color,
球的颜色会有变化,不会和存的 RGB 值完全一样
but merely the closest match.
但会很接近
In more extreme cases, like at a game at night,
如果情况更极端一些,比如比赛是在晚上,
the tracking might be poor.
追踪效果可能会很差
And if one of the team's jerseys used the same color as the ball,
如果球衣的颜色和球一样,
our algorithm would get totally confused.
算法就完全晕了
For these reasons, color marker tracking and similar algorithms are rarely used,
因此很少用这类颜色跟踪算法
unless the environment can be tightly controlled.
除非环境可以严格控制
This color tracking example was able to search pixel-by-pixel,
颜色跟踪算法是一个个像素搜索,
because colors are stored inside of single pixels.
因为颜色是在一个像素里
But this approach doesn't work for features larger than a single pixel,
但这种方法 不适合占多个像素的特征
like edges of objects, which are inherently made up of many pixels.
比如物体的边缘,是多个像素组成的.
To identify these types of features in images,
为了识别这些特征,
computer vision algorithms have to consider small regions of pixels,
算法要一块块像素来处理
called patches.
每一块都叫"块"
As an example, let's talk about an algorithm that finds vertical edges in a scene,
举个例子,找垂直边缘的算法
let's say to help a drone navigate safely through a field of obstacles.
假设用来帮无人机躲避障碍
To keep things simple, we're going to convert our image into grayscale,
为了简单,我们把图片转成灰度,
although most algorithms can handle color.
不过大部分算法可以处理颜色
Now let's zoom into one of these poles to see what an edge looks like up close.
放大其中一个杆子,看看边缘是怎样的
We can easily see where the left edge of the pole starts,
可以很容易地看到 杆子的左边缘从哪里开始
because there's a change in color that persists across many pixels vertically.
因为有垂直的颜色变化
We can define this behavior more formally by creating a rule
我们可以弄个规则说
that says the likelihood of a pixel being a vertical edge
某像素是垂直边缘的可能性,
is the magnitude of the difference in color
取决于左右两边像素的
between some pixels to its left and some pixels to its right.
颜色差异程度
The bigger the color difference between these two sets of pixels,
左右像素的区别越大,
the more likely the pixel is on an edge.
这个像素越可能是边缘
If the color difference is small, it's probably not an edge at all.
如果色差很小,就不是边缘
The mathematical notation for this operation looks like this
这个操作的数学符号 看起来像这样
it's called a kernel or filter.
这叫"核"或"过滤器"
It contains the values for a pixel-wise multiplication,
里面的数字用来做像素乘法
the sum of which is saved into the center pixel.
总和 存到中心像素里
Let's see how this works for our example pixel.
我们来看个实际例子
I've gone ahead and labeled all of the pixels with their grayscale values.
我已经把所有像素转成了灰度值
Now, we take our kernel, and center it over our pixel of interest.
现在把"核"的中心,对准感兴趣的像素
This specifies what each pixel value underneath should be multiplied by.
这指定了每个像素要乘的值
Then, we just add up all those numbers.
然后把所有数字加起来
In this example, that gives us 147.
在这里,最后结果是 147
That becomes our new pixel value.
成为新像素值
This operation, of applying a kernel to a patch of pixels,
把 核 应用于像素块,
is call a convolution.
这种操作叫"卷积"
Now let's apply our kernel to another pixel.
现在我们把"核"应用到另一个像素
In this case, the result is 1. Just 1.
结果是 1

In other words, it's a very small color difference, and not an edge.
色差很小,不是边缘
If we apply our kernel to every pixel in the photo,
如果把"核"用于照片中每个像素
the result looks like this,
结果会像这样
where the highest pixel values are where there are strong vertical edges.
垂直边缘的像素值很高
Note that horizontal edges, like those platforms in the background,
注意,水平边缘(比如背景里的平台)
are almost invisible.
几乎看不见
If we wanted to highlight those features,
如果要突出那些特征
we'd have to use a different kernel
要用不同的"核"
one that's sensitive to horizontal edges.
用对水平边缘敏感的"核"
Both of these edge enhancing kernels are called Prewitt Operators,
这两个边缘增强的核叫"Prewitt 算子"
named after their inventor.
以发明者命名
These are just two examples of a huge variety of kernels,
这只是众多"核"的两个例子
able to perform many different image transformations.
核能做很多种图像转换
For example, here's a kernel that sharpens images.
比如这个"核"能锐化图像
And here's a kernel that blurs them.
这个"核"能模糊图像
Kernels can also be used like little image cookie cutters that match only certain shapes.
核也可以像饼干模具一样,匹配特定形状
So, our edge kernels looked for image patches
之前做边缘检测的"核"
with strong differences from right to left or up and down.
会检查左右或上下的差异
But we could also make kernels that are good at finding lines, with edges on both sides.
但我们也可以做出 擅长找线段的"核"
And even islands of pixels surrounded by contrasting colors.
或者包了一圈对比色的区域
These types of kernels can begin to characterize simple shapes.
这类"核"可以描述简单的形状
For example, on faces, the bridge of the nose tends to be brighter than the sides of the nose,
比如鼻梁往往比鼻子两侧更亮
resulting in higher values for line-sensitive kernels.
所以线段敏感的"核"对这里的值更高
Eyes are also distinctive
眼睛也很独特
a dark circle sounded by lighter pixels -
一个黑色圆圈被外层更亮的一层像素包着
a pattern other kernels are sensitive to.
有其它"核"对这种模式敏感
When a computer scans through an image,
当计算机扫描图像时,
most often by sliding around a search window,
最常见的是用一个窗口来扫
it can look for combinations of features indicative of a human face.
可以找出人脸的特征组合
Although each kernel is a weak face detector by itself,
虽然每个"核"单独找出脸的能力很弱,
combined, they can be quite accurate.
但组合在一起会相当准确
It's unlikely that a bunch of face-like features will cluster together if they're not a face.
不是脸但又有一堆脸的特征在正确的位置,这种情况不太可能
This was the basis of an early and influential algorithm
这是一个早期很有影响力的算法的基础
called Viola-Jones Face Detection.
叫 维奥拉·琼斯 人脸检测算法
Today, the hot new algorithms on the block are Convolutional Neural Networks.
如今的热门算法是 "卷积神经网络"
We talked about neural nets last episode, if you need a primer.
我们上集谈了神经网络,如果需要可以去看看
In short, an artificial neuron
总之,神经网络的最基本单位,
which is the building block of a neural network -
是神经元
takes a series of inputs, and multiplies each by a specified weight,
它有多个输入,然后会把每个输入 乘一个权重值
and then sums those values all together.
然后求总和
This should sound vaguely familiar, because it's a lot like a convolution.
听起来好像挺耳熟,因为它很像"卷积"
In fact, if we pass a neuron 2D pixel data, rather than a one-dimensional list of inputs,
实际上,如果我们给神经元输入二维像素
it's exactly like a convolution.
完全就像"卷积"
The input weights are equivalent to kernel values,
输入权重等于"核"的值
but unlike a predefined kernel,
但和预定义"核"不同
neural networks can learn their own useful kernels
神经网络可以学习对自己有用的"核"
that are able to recognize interesting features in images.
来识别图像中的特征
Convolutional Neural Networks use banks of these neurons to process image data,
卷积神经网络用一堆神经元处理图像数据
each outputting a new image, essentially digested by different learned kernels.
每个都会输出一个新图像,本质上是被不同的"核"处理了
These outputs are then processed by subsequent layers of neurons,
输出会被后面一层神经元处理
allowing for convolutions on convolutions on convolutions.
卷积卷积再卷积
The very first convolutional layer might find things like edges,
第一层可能会发现"边缘"这样的特征
as that's what a single convolution can recognize, as we've already discussed.
单次卷积可以识别出这样的东西,之前说过
The next layer might have neurons that convolve on those edge features
下一层可以在这些基础上识别
to recognize simple shapes, comprised of edges, like corners.
比如由"边缘"组成的角落
A layer beyond that might convolve on those corner features,
然后下一层可以在"角落"上继续卷积
and contain neurons that can recognize simple objects,
下一些可能有识别简单物体的神经元
like mouths and eyebrows.
比如嘴和眉毛
And this keeps going, building up in complexity,
然后不断重复,逐渐增加复杂度
until there's a layer that does a convolution that puts it together:
直到某一层把所有特征放到一起:
eyes, ears, mouth, nose, the whole nine yards,
眼睛,耳朵,嘴巴,鼻子
and says "ah ha, it's a face!"
然后说:"啊哈,这是脸!"
Convolutional neural networks aren't required to be many layers deep,
卷积神经网络不是非要很多很多层
but they usually are, in order to recognize complex objects and scenes.
但一般会有很多层,来识别复杂物体和场景
That's why the technique is considered deep learning.
所以算是"深度学习"
Both Viola-Jones and Convolutional Neural Networks can be applied to many image recognition problems,
维奥拉·琼斯和"卷积神经网络",
beyond faces, like recognizing handwritten text,
不只是认人脸,还可以识别手写文字
spotting tumors in CT scans and monitoring traffic flow on roads.
在 CT 扫描中发现肿瘤,监测马路是否拥堵
But we're going to stick with faces.
但我们这里接着用人脸举例
Regardless of what algorithm was used, once we've isolated a face in a photo,
不管用什么算法,识别出脸之后
we can apply more specialized computer vision algorithms to pinpoint facial landmarks,
可以用更专用的计算机视觉算法,来定位面部标志
like the tip of the nose and corners of the mouth.
比如鼻尖和嘴角
This data can be used for determining things like if the eyes are open,
有了标志点,
which is pretty easy once you have the landmarks
判断眼睛有没有张开就很容易了
it's just the distance between points.
只是点之间的距离罢了
We can also track the position of the eyebrows;
也可以跟踪眉毛的位置
their relative position to the eyes can be an indicator of surprise, or delight.
眉毛相对眼睛的位置 可以代表惊喜或喜悦
Smiles are also pretty straightforward to detect based on the shape of mouth landmarks.
根据嘴巴的标志点,检测出微笑也很简单
All of this information can be interpreted by emotion recognition algorithms,
这些信息可以用"情感识别算法"来识别
giving computers the ability to infer when you're happy, sad, frustrated, confused and so on.
让电脑知道你是开心,忧伤,沮丧,困惑等等
In turn, that could allow computers to intelligently adapt their behavior...
然后计算机可以做出合适的行为.
maybe offer tips when you're confused,
比如当你不明白时 给你提示
and not ask to install updates when you're frustrated.
你心情不好时,就不弹更新提示了
This is just one example of how vision can give computers the ability to be context sensitive,
这只是计算机通过视觉感知
that is, aware of their surroundings.
周围的一个例子
And not just the physical surroundings
不只是物理环境
like if you're at work or on a train -
比如是不是在上班,或是在火车上
but also your social surroundings
还有社交环境
like if you're in a formal business meeting versus a friend's birthday party.
比如是朋友的生日派对,还是正式商务会议
You behave differently in those surroundings, and so should computing devices,
你在不同环境会有不同行为,计算机也应如此
if they're smart.
如果它们够聪明的话...
Facial landmarks also capture the geometry of your face,
面部标记点 也可以捕捉脸的形状
like the distance between your eyes and the height of your forehead.
比如两只眼睛之间的距离,以及前额有多高
This is one form of biometric data,
做生物识别
and it allows computers with cameras to recognize you.
让有摄像头的计算机能认出你
Whether it's your smartphone automatically unlocking itself when it sees you,
不管是手机解锁
or governments tracking people using CCTV cameras,
还是政府用摄像头跟踪人
the applications of face recognition seem limitless.
人脸识别有无限应用场景
There have also been recent breakthroughs in landmark tracking for hands and whole bodies,
另外 跟踪手臂和全身的标记点,最近也有一些突破
giving computers the ability to interpret a user's body language,
让计算机理解用户的身体语言
and what hand gestures they're frantically waving at their internet connected microwave.
比如用户给联网微波炉的手势
As we've talked about many times in this series,
正如系列中常说的,
abstraction is the key to building complex systems,
抽象是构建复杂系统的关键
and the same is true in computer vision.
计算机视觉也是一样
At the hardware level, you have engineers building better and better cameras,
硬件层面,有工程师在造更好的摄像头,
giving computers improved sight with each passing year,
让计算机有越来越好的视力
which I can't say for myself.
我自己的视力却不能这样
Using that camera data,
用来自摄像头的数据
you have computer vision algorithms crunching pixels to find things like faces and hands.
可以用视觉算法找出脸和手
And then, using output from those algorithms,
然后可以用其他算法接着处理,
you have even more specialized algorithms for interpreting things
解释图片中的东西
like user facial expression and hand gestures.
比如用户的表情和手势
On top of that, there are people building novel interactive experiences,
有了这些,人们可以做出新的交互体验
like smart TVs and intelligent tutoring systems,
比如智能电视和智能辅导系统,
that respond to hand gestures and emotion.
会根据用户的手势和表情来回应
Each of these levels are active areas of research,
这里的每一层都是活跃的研究领域
with breakthroughs happening every year.
每年都有突破,
And that's just the tip of the iceberg.
这只是冰山一角
Today, computer vision is everywhere
如今 计算机视觉无处不在
whether it's barcodes being scanned at stores,
商店里扫条形码,
self-driving cars waiting at red lights,
等红灯的自动驾驶汽车
or snapchat filters superimposing mustaches.
或是 Snapchat 里添加胡子的滤镜
And, the most exciting thing is that computer scientists are really just getting started,
令人兴奋的是 一切才刚刚开始
enabled by recent advances in computing, like super fast GPUs.
最近的技术发展,比如超快的GPU,会开启越来越多可能性
Computers with human-like ability to see is going to totally change how we interact with them.
视觉能力达到人类水平的计算机,会彻底改变交互方式
Of course, it'd also be nice if they could hear and speak,
当然,如果计算机能听懂我们然后回话,就更好了
which we'll discuss next week. I'll see you then.
我们下周讨论 到时见